
Machine Learning in Spend Classification: Transforming Procurement Intelligence
Picture this: You’re staring at a spreadsheet with 50,000 rows of spending data, and your boss wants to know exactly how much the company spent on office supplies versus IT services last quarter. Sound familiar? If you’ve ever tried to manually categorize messy procurement data, you know it’s like trying to organize a library after a tornado hit overwhelming and seemingly impossible.
This is where machine learning in spend classification steps in as your digital librarian. Spend classification is the process of organizing and categorizing financial transactions into meaningful buckets, helping organizations understand where their money actually goes. And when you add machine learning to the mix, what used to take weeks of manual work can happen in minutes, with accuracy that puts even the most detail-oriented analyst to shame.
Here’s my thesis: machine learning doesn’t just automate spend classification it revolutionizes procurement by delivering unprecedented accuracy, scalability, and insights that drive real business value.
Table of Contents
What Is Spend Classification?
Let’s start with the basics. Spend classification is essentially the art and science of organizing your company’s expenditures into logical categories. Think of it as creating a filing system for your money instead of throwing all your receipts into one big box, you sort them into folders like “Travel,” “Marketing,” “IT Infrastructure,” and “Office Supplies.”
But why does this matter so much? Well, proper spend classification is the backbone of effective procurement management. It gives you visibility into spending patterns, helps identify cost-saving opportunities, ensures compliance with internal policies, and provides the data foundation for strategic supplier negotiations. Without it, you’re essentially flying blind when it comes to financial decision-making.
The traditional approach to spend classification has been, frankly, a nightmare. Manual categorization is time-consuming, inconsistent, and prone to human error. Different analysts might classify the same expense differently, leading to data that’s about as reliable as weather predictions. Plus, as organizations grow and transaction volumes explode, manual classification becomes practically impossible to scale.
Role of Machine Learning in Spend Classification
This is where artificial intelligence in procurement changes the game entirely. Machine learning algorithms can analyze historical spend data to identify patterns that humans might miss or simply don’t have time to catch. Unlike the rigid rules-based systems of the past, ML models actually learn and adapt from your data.
Traditional rules-based classification works like this: “If supplier name contains ‘Airlines,’ then categorize as Travel.” Simple enough, but what happens when you get an invoice from “Sky Transportation Services” for employee flights? The rule breaks down.
Machine learning-based spend classification, on the other hand, looks at multiple data points simultaneously supplier names, transaction amounts, descriptions, cost centers, historical patterns, and more. It might notice that transactions with certain keywords, from specific suppliers, within certain amount ranges, almost always belong to particular categories.
Here’s a real-world example that illustrates the difference beautifully: Imagine you have an expense from “Global Tech Solutions LLC” for $5,000. A rules-based system might automatically throw this into “IT Services” based on the word “Tech.” But an ML model might look deeper and notice that similar amounts from this vendor, combined with specific description patterns and timing, actually represent travel booking services for technical conferences. The machine learning algorithm picks up on these subtle contextual clues that rigid rules simply can’t handle.
How Machine Learning Works in Spend Classification
The machine learning process for spend analysis follows a fairly straightforward workflow, though the underlying complexity is quite sophisticated.
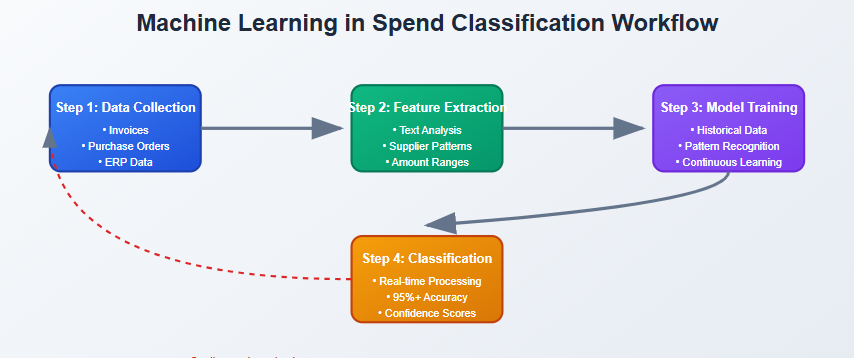
Step 1: Data Collection is where everything begins. The system ingests data from multiple sources invoices, purchase orders, ERP system exports, credit card transactions, and expense reports. This creates a comprehensive dataset that captures the full picture of organizational spending.
Step 2: Feature Extraction is where the magic starts happening. The ML system doesn’t just look at obvious fields like “supplier name” or “amount.” It analyzes text descriptions using natural language processing, identifies patterns in vendor relationships, examines cost center associations, and even considers seasonal spending trends. Each piece of information becomes a “feature” that helps the model make better decisions.
Step 3: Model Training and Continuous Learning is perhaps the most crucial phase. The algorithm studies thousands or even millions of historical transactions that have been correctly classified, learning the relationships between various features and their proper categories. But here’s the key difference from traditional systems the model keeps learning from new data, continuously improving its accuracy over time.
Step 4: Automated Categorization at Scale is where you see the real payoff. Once trained, the system can process new transactions in real-time, automatically assigning categories with confidence scores. Transactions with high confidence scores get processed automatically, while edge cases with lower confidence get flagged for human review.
If you were to visualize this workflow, you’d see a continuous cycle where data flows in, gets processed and classified, and the results feed back into the system to make future classifications even better.
Key Benefits of Machine Learning in Spend Classification
The improvements that predictive analytics in procurement delivers are honestly pretty remarkable. While manual classification typically achieves accuracy rates of 70-80% (and that’s being generous), well-trained machine learning models routinely hit 95% accuracy or higher. That difference isn’t just impressive on paper it translates to real business value.
Scalability is another game-changer. I’ve seen organizations struggle for months to classify spending data that an ML system can process in hours. We’re talking about handling millions of transactions without breaking a sweat, something that would require an army of analysts working around the clock to accomplish manually.
The cost savings and efficiency gains are substantial too. Beyond the obvious labor cost reductions, better spend classification leads to improved supplier consolidation opportunities, more effective contract negotiations, and identification of maverick spending that might otherwise slip through the cracks. One manufacturing company I know of discovered they were inadvertently paying three different rates for essentially the same service from different suppliers insights that only became visible after implementing automated spend classification.
Perhaps most importantly, enhanced supplier insights give procurement teams unprecedented negotiation leverage. When you can clearly demonstrate spending patterns and volumes across categories, you’re in a much stronger position to negotiate better terms and identify strategic partnership opportunities.
Challenges & Limitations
Now, let’s be honest about the obstacles. Data quality issues remain the biggest headache. Machine learning models are only as good as the data they’re trained on, and if your invoices are incomplete, inconsistent, or just plain messy, the results will reflect that. Garbage in, garbage out a principle that’s particularly relevant here.
Model bias and misclassification can also be problematic. If your historical data has systematic errors or biases, the ML model will learn and perpetuate those mistakes. This is why human oversight remains crucial, especially during the initial implementation phases.
Integration challenges with existing ERP and procurement systems can’t be ignored either. Getting all your systems to talk to each other smoothly often requires significant technical expertise and sometimes custom development work.
The reality is that successful implementation requires ongoing attention and refinement. It’s not a “set it and forget it” solution, despite what some vendors might suggest.
Real-World Applications & Use Cases
The applications of automated spend categorization span across industries and use cases. Global manufacturing companies are using ML-powered spend classification to identify consolidation opportunities across their supplier base, often discovering they can reduce their vendor count by 30-40% without sacrificing quality or service.
Fraud detection and duplicate transaction identification represent another powerful application. ML models can spot unusual patterns that might indicate fraudulent activity or catch duplicate invoices that manual processes might miss. One healthcare organization discovered they were paying the same invoice twice because slight variations in formatting fooled their traditional systems.
In retail, companies are using machine learning to better understand seasonal spending patterns and optimize their procurement strategies accordingly. Manufacturing firms leverage these insights to improve supplier relationship management and identify opportunities for strategic partnerships.
The key is that these aren’t just theoretical benefits I’m talking about real organizations achieving measurable results through intelligent spend classification.
Best Practices for Implementing Machine Learning in Spend Classification
If you’re considering implementing smart procurement technologies in your organization, start with your data foundation. Clean, structured spend data is absolutely essential for success. It’s worth investing time upfront to standardize your data formats and improve data quality before even thinking about machine learning.
Industry-specific training makes a huge difference too. Generic models might work okay, but models trained on data from your specific industry will perform significantly better. The spending patterns in healthcare are quite different from those in manufacturing, and your ML model should reflect those nuances.
Maintaining a “human-in-the-loop” approach is crucial, especially in the early stages. Let the machine learning handle the obvious classifications, but keep experienced professionals involved for edge cases and ongoing model refinement.
Finally, choose scalable solutions that integrate well with your existing systems. The last thing you want is a powerful ML model that can’t communicate with your ERP system or requires constant manual data transfers.
Conclusion
Machine learning in spend classification isn’t just another technology trend it’s a fundamental shift in how organizations can understand and manage their financial data. The combination of improved accuracy, massive scalability, and deeper insights makes this technology increasingly essential for competitive procurement operations.
Looking ahead, I expect we’ll see even broader adoption across procurement functions, with ML becoming as standard as spreadsheet software is today. As I discussed in my previous post about “what is ai,” these technologies are becoming more accessible and practical for organizations of all sizes.
If you’re in procurement leadership, now is the time to seriously evaluate how machine learning could transform your spend analysis capabilities. The organizations that embrace these tools early will have significant advantages in cost management, supplier relationships, and strategic decision-making. And unlike some of the concerns I raised in “has ai gone too far,” this application of AI actually solves real business problems without creating ethical dilemmas.
The future of procurement is data-driven, and machine learning in spend classification is your gateway to that future. The question isn’t whether you’ll eventually adopt these technologies it’s whether you’ll be an early adopter who gains competitive advantage, or a late follower playing catch-up.
How accurate is machine learning compared to manual spend classification?
Machine learning models typically achieve 95%+ accuracy rates, significantly higher than the 70-80% accuracy of manual classification. This improvement comes from the system’s ability to analyze multiple data points simultaneously and learn from patterns humans might miss.
What’s the biggest challenge when implementing ML for spend classification?
Data quality is the primary obstacle dirty, incomplete, or inconsistent invoice data will produce poor results regardless of how sophisticated your ML model is. Organizations need to invest in cleaning and standardizing their data before implementation.
Can machine learning completely replace human involvement in spend classification?
No, human oversight remains essential, especially for edge cases and ongoing model refinement. The best approach is “human-in-the-loop” where ML handles obvious classifications while professionals review exceptions and continuously improve the system.
How long does it take to see results from ML-powered spend classification?
Most organizations see initial results within 2-3 months of implementation, with accuracy improving over time as the model learns from more data. The exact timeline depends on data quality and the complexity of your spending categories.
- How to Choose an AI Tool In 2026 Beginner’s Guide

- 20+ Best Free AI Tools for College Students (2026)

- Best Free AI Video Generators In 2026

- Free AI Image Generators for Beginners (2026)

- AI Tools to Automate Daily Tasks

- 10 Free AI Tools Everyone Should Try in 2026

Leave a Comment